Data Builder
Le Data Builder Archie Core est une interface de modélisation de données pour définir des tables de base de données, des types de champs et des relations entre les tables.
Pour ouvrir le Data Builder, cliquez sur Modèle de Données dans la barre latérale, sélectionnez la table sur laquelle vous souhaitez travailler, puis cliquez sur l’onglet Schéma.
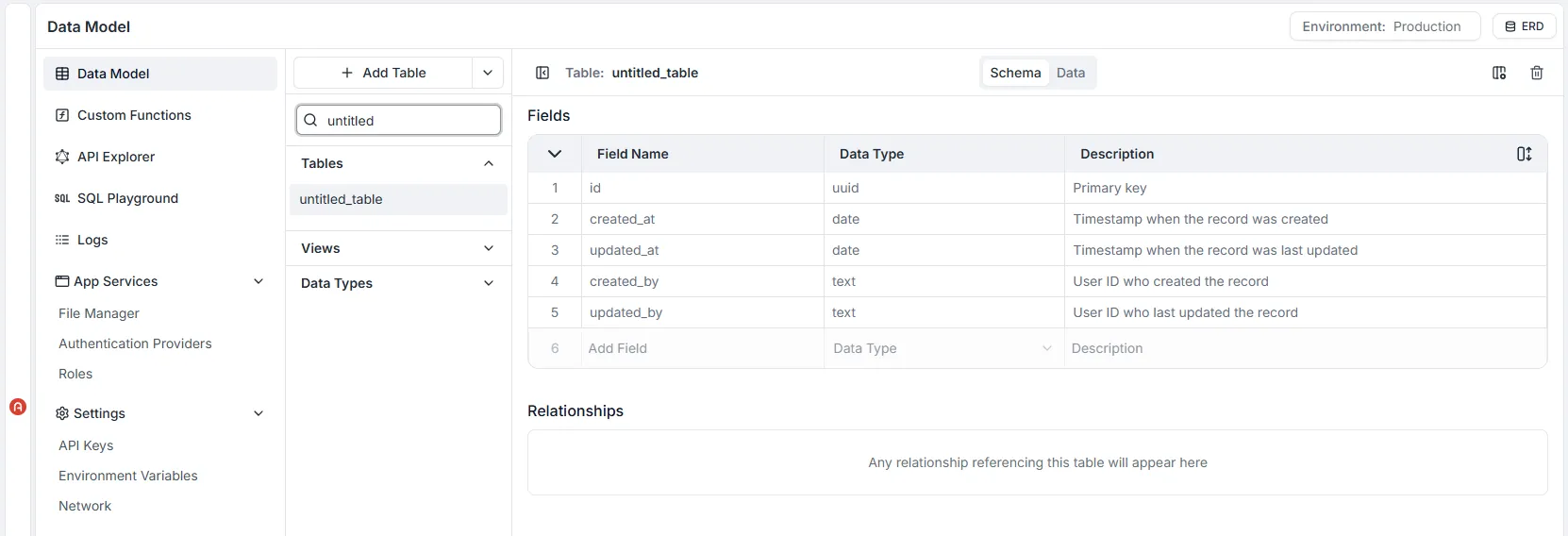
Pour chaque table définie, le moteur GraphQL d’Archie Core crée automatiquement des types d’objets de schéma GraphQL et les champs de requête, de mutation et d’abonnement correspondants avec des résolveurs.
Cela signifie que toutes les actions Créer, Lire, Mettre à jour et Supprimer (CRUD), ainsi que les connexions en temps réel (websockets) sont immédiatement disponibles pour être utilisées via le point de terminaison API unique de l’espace de travail.
Travailler avec des Tables
Section intitulée « Travailler avec des Tables »En arrière-plan, Archie Core provisionne une instance de base de données PostgreSQL dédiée pour votre espace de travail. PostgreSQL est une base de données relationnelle-objet open source avancée connue pour sa fiabilité et l’intégrité de ses données. Elle gère efficacement les requêtes complexes et prend entièrement en charge la conformité ACID (Atomicité, Cohérence, Isolation, Durabilité).
Création de Tables
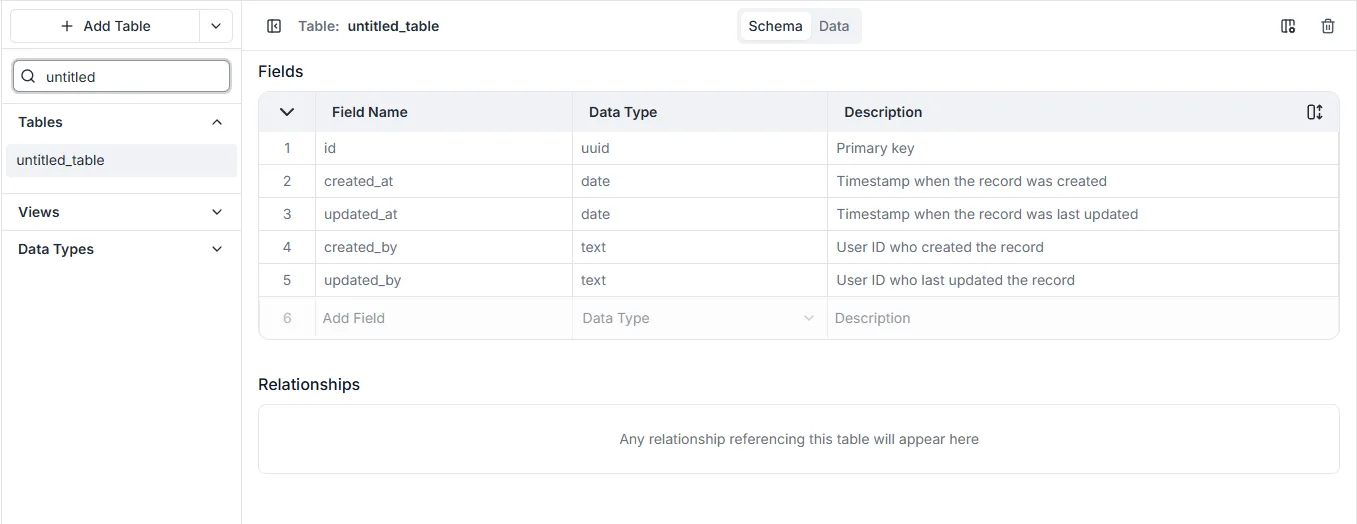
Section intitulée « Création de Tables »Cliquez sur le bouton + Ajouter une Table (+ Add Table) pour créer une nouvelle table. Le nom par défaut pour les nouvelles tables est “untitled_table”. Toutes les tables nécessitent des noms uniques (les noms attribute, workspace et leur forme plurielle sont réservés et ne peuvent être utilisés dans aucune casse).
Dès qu’une table est créée, les types de schéma GraphQL correspondants et les résolveurs de requête, de mutation et d’abonnement seront générés automatiquement.
Mise à Jour des Tables
Section intitulée « Mise à Jour des Tables »Une fois qu’une table est créée, des champs et des relations peuvent être définis. Toutes les mises à jour d’une table sont publiées en temps réel, offrant une expérience transparente entre la définition d’un modèle de données et sa haute disponibilité.
Dès qu’une table est mise à jour, ses types de schéma GraphQL correspondants et ses résolveurs de requête, de mutation et d’abonnement seront mis à jour automatiquement.
Pour garantir que les erreurs liées aux tables sont minimisées, Archie Core protège contre de nombreuses actions nuisibles. Certaines d’entre elles incluent :
- Une invite nécessitant une Valeur par Défaut apparaîtra lors du changement d’un champ non obligatoire à obligatoire.
- Les valeurs des champs Date, Nombre et Texte sont automatiquement converties lorsqu’un type de champ existant est mis à jour.
- Lors du changement d’un champ non unique à unique, les enregistrements actuels sont validés pour avoir des valeurs uniques.
Suppression de Tables
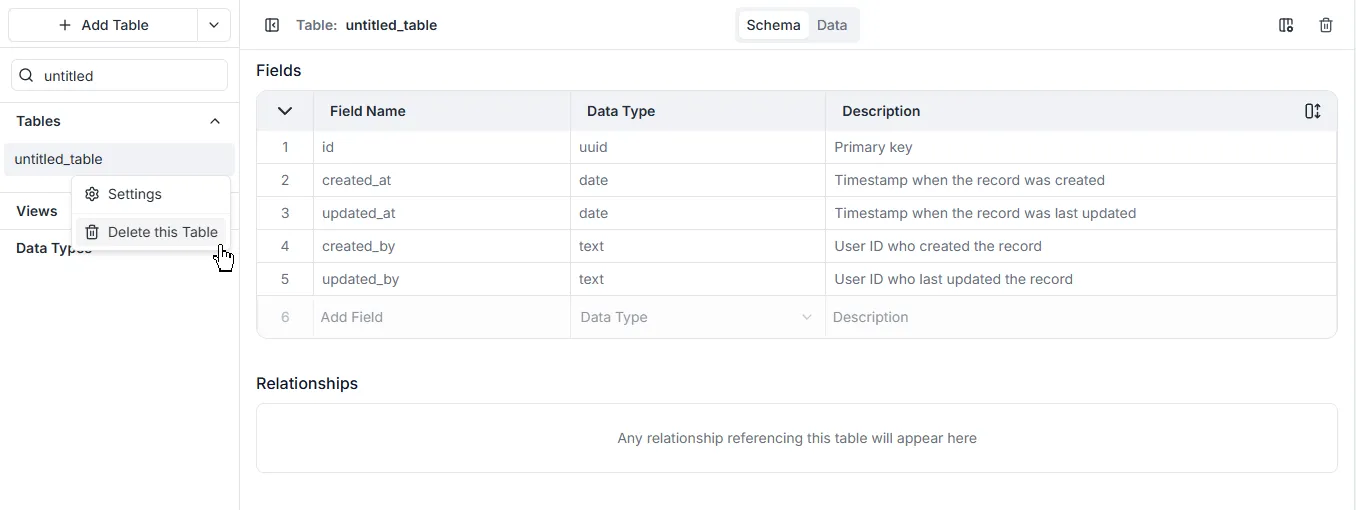
Section intitulée « Suppression de Tables »Pour supprimer une table :
- Allez au nom de la table et cliquez sur
... - Cliquez sur Supprimer cette Table (Delete this Table).
- Une boîte de dialogue de confirmation s’ouvre. Tapez le nom de la table et cliquez sur Supprimer (Delete).
Danger : Les tables supprimées ne peuvent pas être restaurées et tous les enregistrements de table existants seront perdus. De plus, s’il y a des tables liées à la table en cours de suppression - appartient à et a plusieurs, qu’elles soient spécifiées comme obligatoires ou non - ces relations seront rompues.
Relations de Table
Section intitulée « Relations de Table »Archie Core prend en charge trois types de relations de table à définir qui sont conformes à ce que l’on peut attendre des bases de données relationnelles :
| Type | A vers B | B vers A |
|---|---|---|
| un-à-un | Les enregistrements de la table A peuvent avoir_un (have_one) ou appartenir_à (belong_to) des enregistrements de la table B. | Les enregistrements de la table B peuvent avoir_un (have_one) ou appartenir_à (belong_to) des enregistrements de la table A. |
| un-à-plusieurs | L’enregistrement de la table A peut avoir_plusieurs (have_many) enregistrements de la table B. | Les enregistrements de la table B peuvent avoir_un (have_one) ou appartenir_à (belong_to) des enregistrements de la table A. |
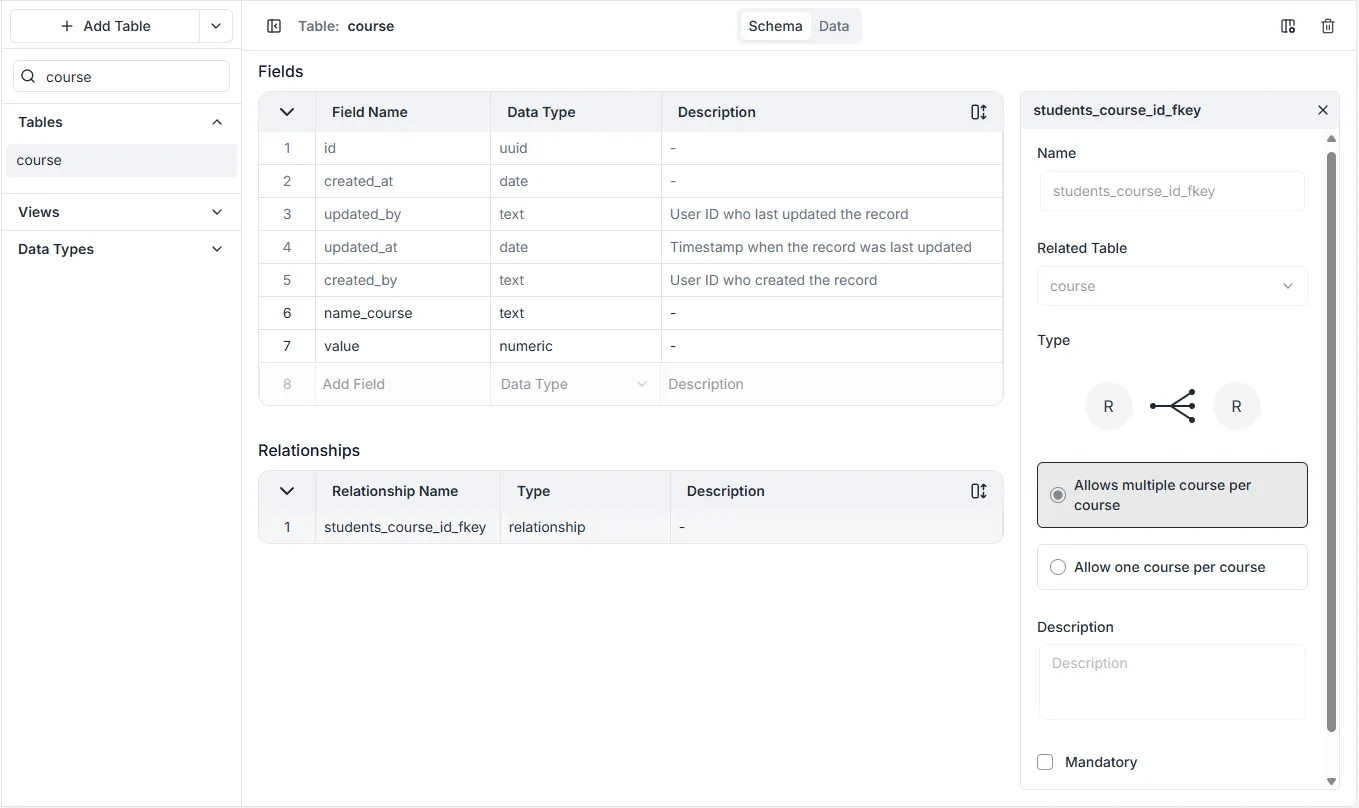
Définir une relation entre deux tables peut être accompli en faisant glisser et déposer une table sur une autre ou en sélectionnant Table comme Type de Données lors de la création d’un nouveau champ de table.
Configurations de Table
Section intitulée « Configurations de Table »Pour spécifier les relations a plusieurs, a un et appartient à entre les tables.
Configurations
- Nom : Pour sélectionner quelle table doit être liée.
- Table Liée : Le nom de la relation tel qu’il apparaît sur la table correspondante.
- Type : Si la relation est a un ou a plusieurs.
- Description : Une zone de texte facultative où vous pouvez écrire des informations sur le champ.
- Obligatoire : Si la relation de champ est requise.
Types de Table
Section intitulée « Types de Table »Il existe trois types de tables : Personnalisé (Custom), Vue (View) et Type de Données (Data Type).
Tables Personnalisées
Section intitulée « Tables Personnalisées »Les tables personnalisées sont les tables créées dans n’importe quel espace de travail par un administrateur. Elles sont entièrement personnalisables.
Tables de Vue
Section intitulée « Tables de Vue »Les Tables de Vue sont des tables virtuelles qui agrègent des champs de plusieurs tables dans une seule vue. En coulisses, elles sont basées sur le jeu de résultats d’une instruction SQL. Dans un espace de travail, elles peuvent être créées à l’aide de la mutation GraphQL viewCreate dans l’Explorateur d’API.
Type de Données
Section intitulée « Type de Données »Les Types vous permettent de définir un ensemble statique et ordonné de valeurs mutuellement exclusives. Contrairement aux champs de texte standard, une Énumération (Enum) restreint la saisie de données à une liste spécifique de constantes prédéfinies.
Les exemples courants incluent des indicateurs d’état (par exemple, BROUILLON, PUBLIÉ, ARCHIVÉ), des rôles d’utilisateur ou des étiquettes de catégorie.
Utilité et Avantages
Section intitulée « Utilité et Avantages »L’utilisation d’Énumérations dans votre schéma de base de données offre plusieurs avantages clés :
- Intégrité des Données : Les Énumérations appliquent une validation stricte des données au niveau de la base de données. Puisque le champ n’accepte que des valeurs de la liste définie, cela élimine les erreurs causées par des fautes de frappe ou des conventions de nommage incohérentes (par exemple, empêchant un mélange de “Haut”, “haut” et “Hi” pour un champ de priorité).
- Cohérence du Code : Elles fournissent une source unique de vérité pour les valeurs autorisées, rendant la logique de l’application plus prévisible et plus facile à maintenir.
- Lisibilité : Les Énumérations rendent les données auto-descriptives. Une valeur comme
PAIEMENT_ÉCHOUÉest beaucoup plus significative pour les développeurs et les analystes qu’un code numérique arbitraire commecode_erreur: 3. - Performance : Dans PostgreSQL, les Énumérations sont stockées efficacement en coulisses mais présentées sous forme de chaînes lisibles, offrant un équilibre entre performance et lisibilité humaine.